Netizen-Style Commenting on Fashion Photos – Dataset and Diversity Measures
Wen Hua Lin, Kuan-Ting Chen, Hung Yueh Chiang, Winston Hsu
Abstract
Recently, image captioning has appeared promising, which is expected to widely apply in chatbot area. Yet, “vanilla” sentences, only describing shallow appearances (e.g., types, colors), generated by current works are not satisfied netizen style resulting in lacking engagement with users. Hence, we propose Netizen Style Commenting (NSC), to generate characteristic comments to a user-contributed fashion photo. We are devoted to modulating the comments in a vivid netizen style which reflects the culture in a designated social community and hopes to facilitate more engagement with users. In this work, we design a novel framework that consists of three major components: (1) We construct a large-scale clothing dataset named NetiLook to discover netizen-style comments. (2) We propose three unique measures to estimate the diversity of comments. (3) We bring diversity by marrying topic models with neural networks to make up the insufficiency of conventional image captioning works.Publication
-
Wen Hua Lin, Kuan-Ting Chen, HungYueh Chiang, Winston H. Hsu. Netizen-Style Commenting on Fashion Photos – Dataset and Diversity Measures, WWW 2018 [arXiv pdf]
@inproceedings{Hsieh_2017_ICCV,
Author = {Meng-Ru Hsieh and Yen-Liang Lin and Winston H. Hsu},
Booktitle = {The IEEE International Conference on Computer Vision (ICCV)},
Title = {Drone-based Object Counting by Spatially Regularized Regional Proposal Networks},
Year = {2017},
organization={IEEE}
}
Dataset
Please notice that this dataset is made available for academic research purpose only. Images are collected from Lookbook, and the copyright belongs to the original owners. If any of the images belongs to you and you would like it removed, please kindly inform us, we will remove it from our dataset immediately.
NetiLook Dataset
NetiLook contains 355,205 images from 11,034 users and 5 million associated comments collected from Lookbook. The downloaded dataset contain following structures:- Images - contains 355,205 images
- Examples:
- 123456789 is post ID
- You can file image of it in img/123/456/789/01.jpg
- Metadata - information about posts in SQL format
- There two table in the SQL file
- Posts
- Information about posts
- Users
- Information about the owners of posts
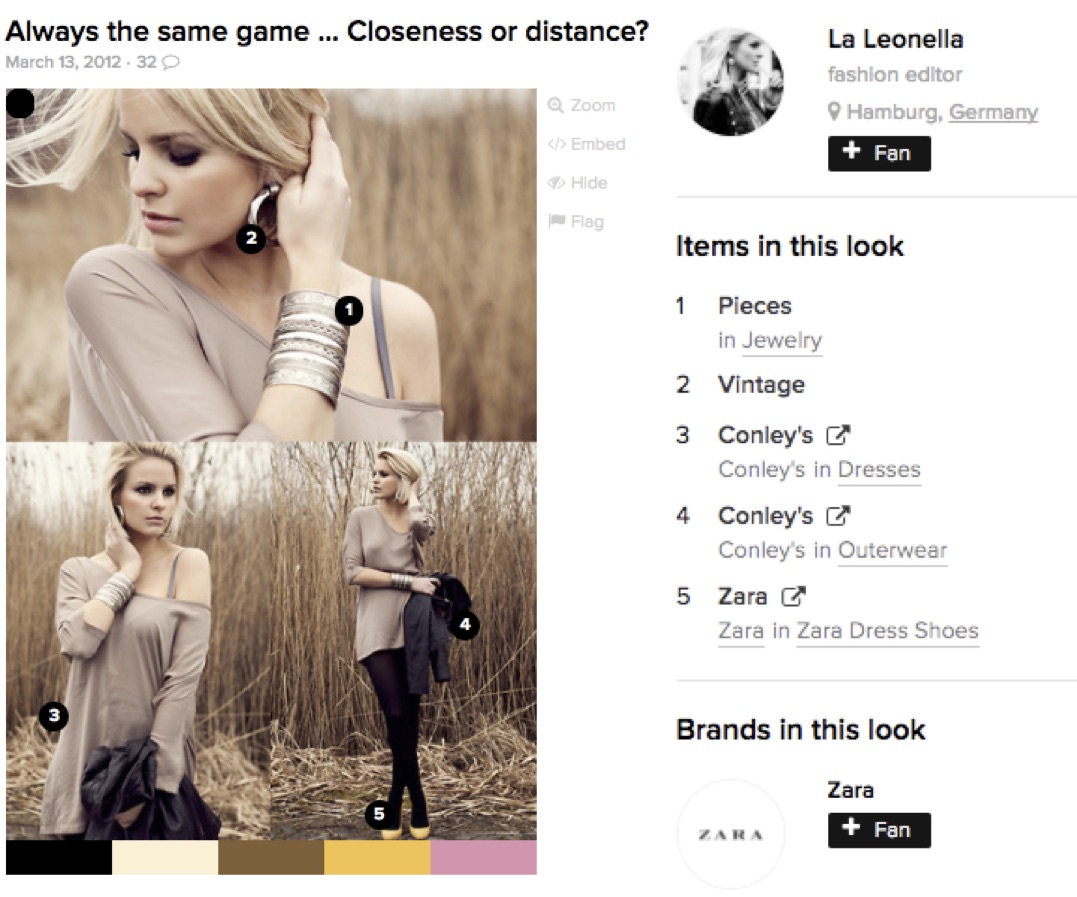
- Content of Phanton, Items and Comments in Posts are JSON format.
- Examples:
- Phanton
- [{"#ead0cd": "offwhite"}, {"#000000": "black"}, {"#8c4600": "brown"}]
- Items
- [[{"Name": "Shirt"}, {"Brand": null}, {"Store": null}, {"X": 221}, {"Y": 203}]]
- X and Y are the position of the item in the image taged by the user
- Comments
- [[{"Name": "Tonka K."}, {"Url": "http://lookbook.nu/tonkakatie"}, {"Comment": "nice wegdes :D hype! check out my new look! ;))"}]]
- All files are encoded with a password. Please, read and fill in the online EULA form before downloading the database. Once we've received the EULA form, we will e-mail you the password for the files.
- Download images of NetiLook dataset from [here]
- Download metadata of NetiLook dataset from [here]
- Download file list and ground truth used in our experiment from [here]
- If you have any problems downloading the data, do not hesitate to contact us at my e-mail address.
Notes
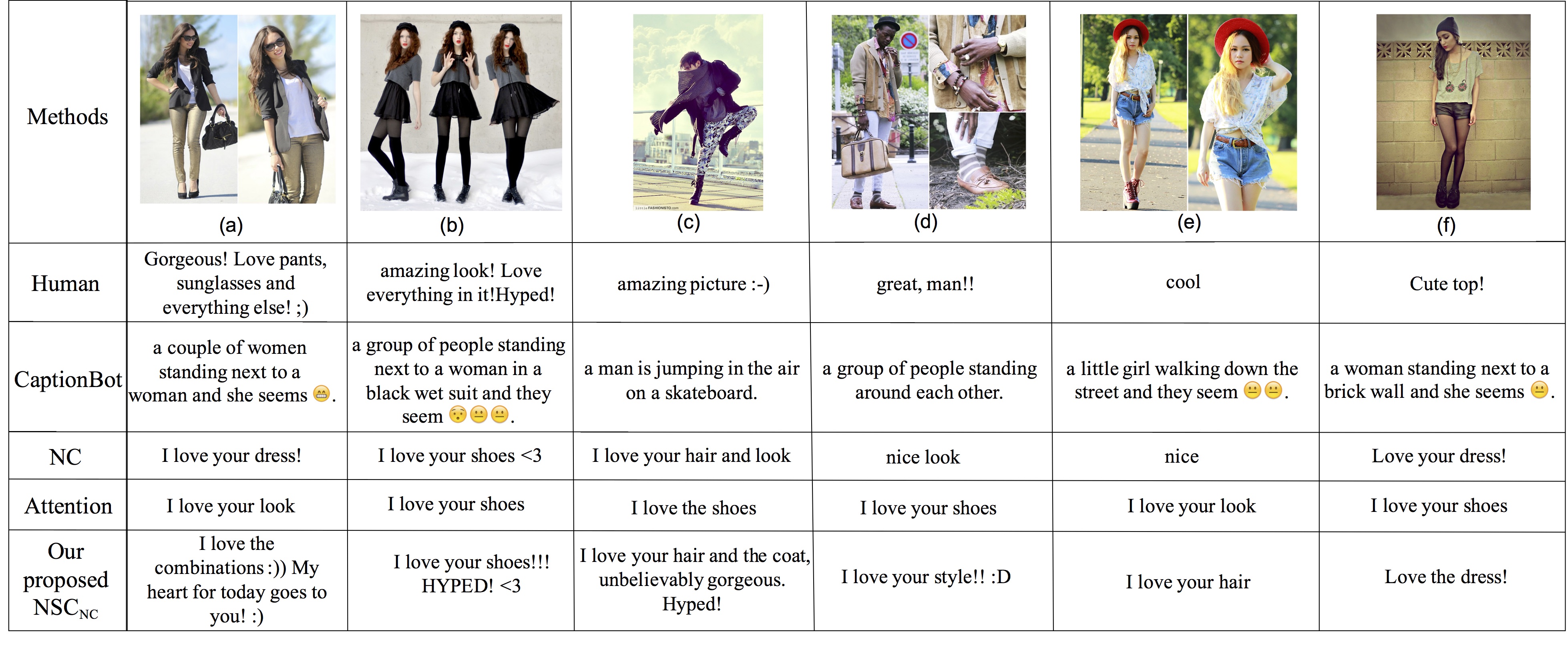
*For evaluation of human, we pick one sentence from the dataset as the answer of human and others as the ground truth.*For comparision with scores of human, we pick four sentences from ground truth to evaluate methods.
Dataset description
To the best of our knowledge, this is the first and the largest netizen-style commenting dataset. It contains 355,205 images from 11,034 users and 5 million associated comments collected from Lookbook. As the examples shown in Figure 1, most of the images are fashion photos in various angles of views, distinct filters and different styles of collage. As Figure 2 (b) shows, each image is paired with (diverse) user comments, and the average number of comments is 14 per image in our dataset. Besides, each post has a title named by an author, a publishing date and the number of hearts given by other users. Moreover, some users add names, brands, pantone of the clothes, and stores where they bought the clothes. Furthermore, we collect the authors’ public information. Some of them contain age, gender, country and the number of fans (cf., Figure 3). In this paper, we only use the comments and the photos from our dataset. Other attributes can be used to refine the system in future work. For comparing the results on Flickr30k, we also sampled 28,000 for training, 1,000 for validation and 1,000 for testing. Besides, we also sampled five comments for each image.
Compared to general image captioning datasets such as Flickr30k (Rashtchian et al. 2010), the data from social media are quite noising, full of emojis, emoticons, slang and much shorter (cf., Figure 2 (b) and Table 1), which makes generating a vivid netizen style comment much more challenging. Moreover, plenty of photos are in different styles of collage (cf., photos in Figure 1). Therefore, it makes the image features much more noising than single view photos.


| Dataset | Images | Sentences | Average Length | Unique words |
| Flickr30k | 30K | 150K | 13.39 | 23,461 |
| MS COCO | 200K | 1M | 10.46 | 54.231 |
| NetiLook | 350K | 5M | 3.75 | 597,629 |
Experimental Results
Performance on Flickr30k testing splits
In Flickr30k, style-weight does not improve much in diversity, because the sentences are objectively depicting humans performing various activities.| Method | BLUE-4 | METEOR | WF-KL | POS-KL | DicRate |
| Human | 0.108 | 0.235 | 1.090 | 0.013 | 0.664 |
| NC | 0.094 | 0.147 | 1.215 | 0.083 | 0.216 |
| Attention | 0.121 | 0.148 | 1.203 | 0.302 | 0.053 |
| NSCNC | 0.089 | 0.146 | 1.217 | 0.075 | 0.228 |
| NSCAttention | 0.119 | 0.148 | 1.202 | 0.319 | 0.055 |
Performance on NetiLook testing splits
Style-weight can guide the generating process to the comment that is much closer to the users’ behaviour in the social media, making machine mimic online netizen comment style and culture.| Method | BLUE-4 | METEOR | WF-KL | POS-KL | DicRate |
| Human | 0.008 | 0.172 | 0.551 | 0.004 | 0.381 |
| NC | 0.013 | 0.151 | 0.665 | 1.126 | 0.036 |
| Attention | 0.020 | 0.133 | 0.639 | 1.629 | 0.011 |
| NSCNC | 0.013 | 0.172 | 0.695 | 0.376 | 0.072 |
| NSCAttention | 0.030 | 0.139 | 0.659 | 1.892 | 0.012 |
User Study
To demonstrate the effect of diverse comments, we conducted a user study from 23 users. The users are about 25 year-old and familiar with netizen style community and social media. The sex ratio in our user study is 2.83 males/female. They are asked to rank comments for 35 fashion photos. Each photo has 4 comments — from one randomly picked human comments, NC, Attention and our NSCNC. Therefore, each of the users has to appraise 140 comments generated from different methods. Furthermore, we collect user feedback to understand user judgements on comments generated by different methods. According to the result, our style-weight makes captioning model mimic human style and generates human-like comments which most people agree with in our user study.
| Ranking | Human | NC | Attention | NSCNC |
| Rank 1 | 46.1% | 10.8% | 6.3% | 36.8% |
| Rank 2 | 24.5% | 21.4% | 14.4% | 39.8% |
| Rank 3 | 18.1% | 31.9% | 34.3% | 15.7% |
| Rank 4 | 11.3% | 35.9% | 45.0% | 7.8% |
Reference
1. Lin, Tsung-Yi, et al. "Microsoft coco: Common objects in context." European conference on computer vision. Springer, Cham, 2014.2. Rashtchian, Cyrus, et al. "Collecting image annotations using Amazon's Mechanical Turk." Proceedings of the NAACL HLT 2010 Workshop on Creating Speech and Language Data with Amazon's Mechanical Turk. Association for Computational Linguistics, 2010.
3. Vinyals, Oriol, et al. "Show and tell: A neural image caption generator." Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
4. Xu, Kelvin, et al. "Show, attend and tell: Neural image caption generation with visual attention." International Conference on Machine Learning. 2015.
5. The photos used in this webiste was collected from lookbook.nu for community research and the copyright belongs to the original owners.
Acknowledgement
This work was supported in part by Microsoft Research Asia and the Ministry of Science and Technology, Taiwan, under Grant MOST 105-2218-E-002-032. We also benefit from the grants from NVIDIA and the NVIDIA DGX-1 AI Supercomputer and the discussions with Dr. Ruihua Song, Microsoft Research Asia.